Optimising Ethereum
The arduous battle of scaling Ethereum's for the masses

Welcome to all the new subscribers over the last few weeks! You can read my last article on Aleph.im here.
Stay up to date with Superfluid by subscribing here:
It’s been well publicised that Ethereum’s network is expensive to use and is losing market share to competitors such as Solana and Avalanche. This issue is nothing new. Transaction costs are like a service fee that increases as more people use the network at any given time and is the main constraint for mainstream adoption of the Ethereum network. Unlike Visa and Mastercard, these costs are borne by the consumer which creates heavy friction from a user experience perspective.
To mitigate this Ethereum is currently working towards shifting to a Proof of Stake consensus mechanism and implementing sharding in the main chain. This will likely scale transactions per second (TPS) to ~100,000, which is well ahead of Visa’s 1,700 TPS, however, Ethereum’s network is used for more than just financial transactions. As a result, various teams around the world have been working towards developing overlaying infrastructure to enhance Ethereum’s network to improve its UX.
Introducing the Layer 2s.
Historical Solution 1: State Channels
Before we dig into the current Layer 2s, it’s worth going back a few years to understand the prior solutions and their pitfalls. The first of which is the State Channel.
The reason why transactions cost so much to process is that they are registered on-chain. But what we care about is the final balances that either party has. So to do that, both parties can deposit their funds into a smart contract, and then transfer money between each other indefinitely without paying transaction costs. Once both parties are satisfied, they can use the smart contract for settlement which will determine the final resulting balances.

However, this method is capitally-inefficient. It requires both parties to deposit funds and becomes tricky if you want to include more parties into the mix as each additional connection will require a new State Channel. Moreover, one of the main benefits of using blockchain technology is being able to have visibility over the transactions that take place on the network.
But this still has the same problem, because the centre itself has to deposit a large number of funds to ensure the capital turnover utilisation rate, and so this solution can only be used for the application of transfers/payments. These limitations with State Channels naturally evolved into a technology called Plasma. Plasma technology was trying to solve the capital utilisation problem of State Channels.
Historical Solution 2: Plasma
Plasma looked to create a tree of blockchains, with a view that processing transactions on a separate blockchain and reconciling them back to the main chain would increase transactions speeds. The challenge here was ensuring that the operators of the side chains didn’t just run away with the funds.
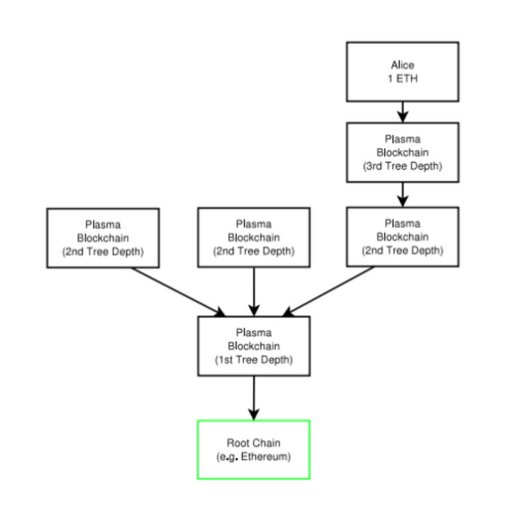
To safeguard against this, Plasma enacted an exit/dispute period of at least one week to ensure the final confirmation of the transaction. During this period, people needed to monitor all transactions on the Plasma chain to ensure that they were legitimate, and challenge transactions if they looked suspicious. This poses a ton of UX issues for ordinary users. As such Plasma evolved into rollup technology.
Current Solution: Rollups
The root cause for many of Plasma’s UX issues was that it kept all the transaction data and computation off-chain. With rollups, some of the data is reconciled back to the main Ethereum blockchain. As a result, unlike other scaling solutions, rollups can support general-purpose EVM code, allowing existing Ethereum based applications to easily migrate over. This makes them easier to adopt by dApps that are increasingly hindered by Ethereum’s slow transaction times.
Rollups come in two different flavours, Optimistic and Zero-Knowledge:
Optimistic
Optimistic rollups build on top of Plasma’s theory of proving whether there are fraudulent transactions in the rollup batch. As the name suggests, once an Optimistic Rollup is reconciled back to Ethereum, the blockchain is optimistic that a given batch of transactions is legitimate. It only rejects this batch if someone submits a valid claim that the transactions are fraudulent.
This is called fraud-proof and is executed as an on-chain transaction. To stop the network from being inundated with fraud proofs, there are incentives in place to promote good behaviour and dissuade bad actors. To be eligible to sequence transactions and bulk register them on-chain, users (sequencers) must post up a bond on Ethereum. This bond is then distributed amongst all verifiers on the network.
As a result, the bigger the bond, there are more incentives for verifiers to ensure transactions are legitimate and less incentive for sequencers to commit fraud. In addition, there is also a dispute period (like plasma) during which verifiers can publish a fraud-proof.
Optimistic rollups are currently being rolled out, with solutions developed by Optimism and Arbitrum. However, these have struggled to gain significant adoption and attention compared to other high throughput Layer 1 chains such as Solana and Avalanche. As of 12/02/2022, Arbitrum and Optimism have only captured a fraction of Ethereum’s Total Value Locked at 1.7% and 0.2% respectively.

Zero-Knowledge
The other competing solution to Optimistic rollups is Zero-knowledge Rollups (ZKR). ZKRs use validity proofs with embedded cryptography to scale blockchains. The idea of Zero-knowledge proofs is not new, having been introduced back in a 1980s academic paper. ZKPs are founded on the basis that someone can prove the truth of information to a verifier without revealing the information itself.
Huh?
Isn’t that impossible? How can you possibly prove something that exists without actually revealing it?
The easiest way to demonstrate this concept is through the beloved series, Where’s Wally?.

Once you’d located Wally amongst a sea of illustrations you would point him out on the page or give away his position through landmarks (hint: Wally is standing next to the mini train carriages). By doing so, you prove that you know where Wally is, but also give up the information about his exact position.
With a Zero-knowledge proof, you wouldn’t need to describe where Wally is. Instead, imagine placing a piece of paper over the page and cutting a small hole in the middle.

This then proves to the verifier that you do indeed know where Wally is without actually showing the exact location of him on the page, meaning the verifier doesn’t gain any knowledge.
In the instance where the prover shows this bear instead, then the verifier knows the prover is lying.

The aim with Zero-knowledge proofs is to show the verifier that you know the secret code/password/whatever it is without actually providing that information. Zero-knowledge proofs have the following structure:
Completeness: A true claim should be sufficient to reach a conclusion
Soundness: If a false claim is provided, then under no scenario can the verifier be convinced that it is true
Zero-knowledge: No further knowledge needs to be provided other than the proof itself.
Here’s a video explanation of Zero-Knowledge proofs that I found quite helpful.
There are two different types of Zero-knowledge proofs: zk-SNARKs and zk-STARKs.
SNARK stands for Succinct, Non-interactive, ARgument of Knowledge.
Succinct
This means that proofs can be verified within a few milliseconds, with proofs that are at most a few hundred bytes. This means that the verification time doesn’t increase greatly despite the computation load.
Non-Interactive
Traditionally with a Zero-knowledge proof, the prover and verifier would interact a few times to establish credibility. However, with more interaction, the process is drawn out, slowing down the entire process and negatively affecting scalability. In a Non-Interactive proof, it is simply a single message from prover to verifier.
ARguments of Knowledge
Argument is used interchangeably with proofs. zk-SNARKs are computationally sound, which means that provers have a low chance of being able to fraud the system.
In addition to these characteristics, zk-SNARKs are dependent on trusted parameters that are set between a prover and verifier (also known as a trusted setup). These parameters are encoded into the protocol and are one of the necessary factors in proving a transaction was valid. However, this creates some centralisation as there is a small team that decrees what the trusted parameters are. As a result, zk-STARKs provide a way to use Zero-knowledge proofs without this trust element.
STARK stands for Scalable, Transparent, ARgument of Knowledge.
Scalable
STARK proofs are slightly larger in size compared to SNARKs, however, are constructed in a way that makes them more scalable as the number of transactions increases. Effectively, there are a few different types of complexities that need to be accounted for when using both STARKs and SNARKs. These are Arithmetic circuits, Communication, Prover, and Verifier complexities. In a gross oversimplification, with SNARKs, these complexities generally increase linearly which means it can result in less scalability for the network (longer transaction times). With STARKs, these largely hold stable over time, meaning that despite slightly large proof sizes (in kilobytes), the user experience from a transaction speed perspective stays relatively stable.
Transparent
To fix some of the centralisation issues found in SNARKs, STARKs use publicly verified randomness to create each proof. This means that everyone can see the parameters under which a proof was confirmed to ensure no bad behaviour has occurred.
At the moment, both zk-SNARKs and zk STARKs are in development by zkSync and Starkware respectively. Various protocols such as Immutable, dYdX, and Sorare use StarkWare’s solution to scale transactions whilst zk-SNARKs are used by Loopring and Mina.
Summarising the above into a digestible table, the key takeaway here is that zk-rollups are the best solution to scaling the Ethereum network from a consumer UX perspective.

The transition from building on Layer 1s to Layer 2s
So all of this sounds great, but why aren’t more protocols and dApps using rollups to lower gas fees and improve performance?
Stepping back a bit, to launch dApps on Ethereum, developers make use of the Ethereum Virtual Machine (EVM). As Ethereum can handle smart contracts, it needs to consolidate the state of the network after each block (meaning it has to reconcile all ETH accounts and balances). The EVM’s main purpose is to determine what the overall state of Ethereum will be for each block in the blockchain.
Since Ethereum is so dominant, other Layer 1 blockchains are EVM compatible. This also applies to rollups. By being EVM-compatible, it allowed projects to move fast, without needing to create their own EVM in the rollup smart contract. This is good enough for almost every application but for rollups to succeed they need EVM equivalence.
EVM equivalence means that the Layer 2 solution and all of its modules are completely compliant with Ethereum, which means that any bytecode that can be run on the main ETH network can be run in its layer 2 counterparts. This will make it easier for dApps and protocols to migrate their codebase without having to do a strenuous amount of extra work to retrofit a Layer 2 solution. At the moment, Optimism has achieved EVM equivalence.
Investing in Layer 2 Technology
Up to this point, we’ve discussed the past and present solutions to Ethereum’s scalability dilemmas. Past solutions have failed to stick around due to technological issues, however, with rollups, it seems that these are a lot more enduring. So from an investment lens, what does this mean?
It’s still fairly unclear whether Layer 2s will capture value over the longer term (5-10 years). It will largely be dependent on the tokenomics each token has. In many cases, I would expect them to function similarly to commodities where there is a continual shift in total circulating supply over time depending on demand. Alternatively, if the tokens are not used to pay fees, then they might accrue value exponentially and act as a ‘share’ in the underlying technology.
Whilst none of the big 4 rollup players have tokens, there are a few ways of gaining exposure to Layer 2 technology:
Invest in Layer 2 enabled products such as Immutable or dYdX. This, however, isn’t a pure strategy as value capture is dependent on traffic driven through the product
Invest in ETH with a view that rollups will attract a flood of users who left to other cheaper and faster Layer 1s
Invest in Zero-Knowledge Proof enabled protocols such as Mina, ZCash, and Loopring
Pre-emptively start using zkSync, Starkware, Optimism, and Arbitrum in the hopes that there will be a token airdrop to past users. At the moment, only zkSync has confirmed that it will have a token
What if rollups aren’t the way to go?
On the flip side, maybe rollups are too late to the party. Decentralised apps are already going cross-chain towards Binance Smart Chain, Polygon, or Avalanche and so the reliance on Ethereum as the main network is reduced. This then creates a flow-on effect in that the rollout of rollups is less significant as you can access the protocol through other Layer 1s that offer similar benefits. If this occurs, rollups can win with better UX both from the consumer side (e.g. easier to onboard fiat into them, greater security, easier to implement) and also the developer side (i.e. achieve EVM equivalence).
Let me know what you think is the way forward in the comments below or on Twitter!
Make sure to subscribe now to not miss the next article.
How did you like today’s article? Your feedback helps me make this amazing.
Thanks for reading and see you next time!
Abhi